Shopping Cart Persistence
Pete Tenereillo
12/9/2003
Copyright Tenereillo, Inc. 2003
Abstract
This paper describes and presents various solutions to an issue that often arises in the use of Server Load Balancers (SLBs) for e-commerce or financial applications, or any applications that use a combination of HTTP and HTTPS/SSL. It presents one solution which is in some ways technically superior to that provided by expensive SSL offload equipment. The solution is by no means new, as some customers have been using it successfully for more than half a decade.
I have written several vendor-specific papers on this topic over the years, but decided to create a version of this paper suitable for the public domain. I hope you find it useful!
Overview of the Shopping Cart Persistence Issue
Given the fictitious Web site (or Universal Resource Locator, URL) http://www.buysomebooks.com/, with the following datacenter topology:
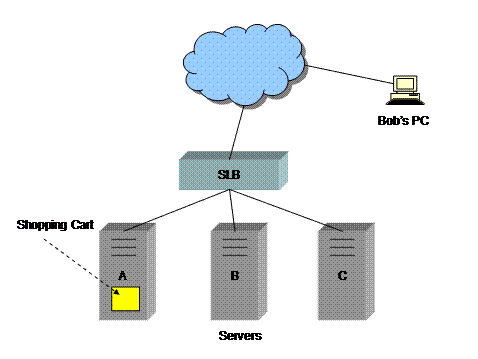
In this example, when “Bob” (the TCP client) first connects to the site, he uses clear text HTTP on port 80. Bob uses the links on the Web site to view descriptions of the books that he wishes to purchase. As Bob follows the links using his Web browser, his Web browser makes a number of subsequent TCP connections (in this example, one TCP connection per HTTP GET request[1]) on Bob’s behalf. This series of TCP connections is called a “session”. Eventually Bob decides to select some books to purchase. He does so by filling out HTML forms on the Web pages and clicking a button called “Add to Shopping Cart”. This shopping cart is just a place in server memory where Bob’s selections are stored. The submission of these HTML forms result in HTTP POST requests to the Web server. Because of the design of this e-commerce software application, where shopping carts are stored on individual servers (as opposed to some shared database), it is required that all TCP connections that are part of Bob’s session be directed to the same server, server “A” in this example. It is the job of the SLB to insure that subsequent HTTP GET requests in Bob’s session are directed to the same server. The practice of directing subsequent requests that are part of the same session to the same server is sometimes referred to as “session persistence”, or just “persistence”. Modern SLBs usually accomplish persistence by the use of HTTP cookies, as shown below.
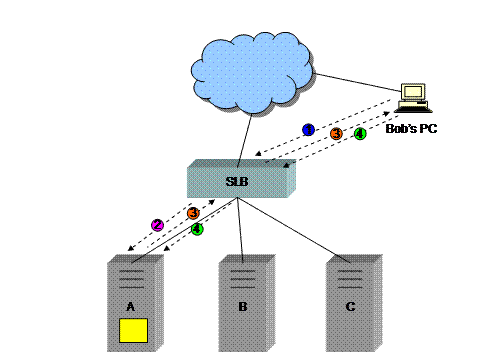
1) The client sends an HTTP GET request to the IP address of the site www.buysomebooks.com, which is a virtual IP address (VIP) on an SLB device. This initial request does not contain a cookie.
2) The SLB decides which server to direct the request to. In this case the SLB selects server A.
3) Server A replies to the HTTP request. The SLB intercepts the reply and inserts an HTTP header field. The header field is the text string “Set-cookie: SLBcookie=serverA”. The SLB returns the HTTP response to the client, and the client stores the cookie either in memory or on disk.
4) On subsequent HTTP (or HTTPS) requests to this site, the client returns the string “Cookie: SLBcookie=serverA”. The SLB intercepts these requests, looks inside the HTTP headers, and determines that the request must be directed to server A.
After Bob has finished selecting books to purchase, he clicks a button called “Check Out”. The Web site now presents Bob with an HTML form, on which he must fill out his shipping address and credit card number. After entering this information Bob clicks a button called “Complete Transaction”. At this point Bob’s Web browser application makes another TCP connection on his behalf, but this time it is an encrypted Secure Sockets Layer (SSL) HTTP POST request (secure HTTP is also called HTTPS). In order to complete the purchase, this HTTPS request must be directed to the same server as the previous HTTP requests in Bob’s session, server A. If the HTTPS request was directed to a different server, that server would not know the contents of the shopping cart, and therefore would not be able to complete the transaction.
Solving the persistence issue for this last (HTTPS) request is a bit more complex. HTTPS is encrypted, and the SSL session is between “Bob’s PC” and server A, not between Bob’s PC and the SLB. The SLB is not able to read the string “Cookie: SLBcookie=serverA” in the HTTPS connection from the client, because that string is in the encrypted portion of the data. The SLB is therefore not able to insure that the request is directed to server A, and all other things being equal in this example, there is only a 1 in 3 chance that the SSL session ends up on server A. Of course if the SSL session ends up on server B or C, the shopping cart is lost.
Many alternative approaches to achieving persistence across HTTP and HTTPS requests in a session have been tried, including the use of various source IP address mapping schemes. A discussion of those is beyond the scope of this document, but it will suffice to say that it is very difficult to obtain reliable persistence via a mechanism on an SLB device without the use of cookies. Because the use of cookies by an SLB for HTTPS sessions is not possible, another solution is clearly needed.
Existing Solutions
Change the application
By far the best way to solve the shopping cart persistence problem is to change the design of the application so that persistence is no longer needed (i.e. such that it no longer matters if subsequent requests that are part of an existing session are directed to the same server). The two most popular ways to achieve this are as follows:
1) Store the session state in HTTP cookies. In the above example this could be done by storing Bob’s book selections in an encoded cookie or in multiple cookies. The selections would be sent with each subsequent request.
2) Store the session state in some shared location, such that all servers can access it. This shared location can be a relational database or just another server or set of servers.
Nevertheless, most Web site development environments, including Microsoft Active Server Pages (ASP), MacroMedia ColdFusion, and PHP: Hypertext Preprocessor, support some sort of session object (for the purpose of making development more convenient). These environments themselves use cookies to save state, and the cookies values and associated session objects must be used on the same server on which they were generated. Once an application is written to make use of session objects, it is usually not desirable to rewrite it.
Change the Protocol: SSL Offload or Termination
Another way to solve the persistence issue is to decrypt the data before it enters the SLB device. This way the SLB device can read the HTTP cookie, use the same persistence mechanism that it uses for clear text HTTP traffic, and direct requests accordingly. The diagram below shows a typical topology[2]:
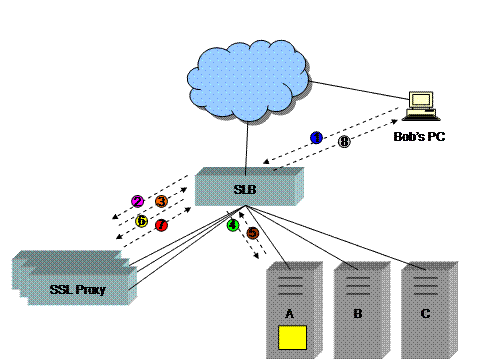
0) (Not shown in diagram) As before, Bob’s PC makes an initial HTTP GET request in clear text to a VIP on the SLB device. The SLB identifies the request using the TCP port number (80 in the case of HTTP). The request is load balanced to server A, server A replies, and a cookie is inserted by the SLB device. Some number of subsequent HTTP GET or POST requests are directed to server A.
1) Bob’s PC now makes an HTTPS POST request. An HTTP cookie is sent with the request, but is in the encrypted portion of the request. The TCP port number in this example is 443.
2) The SLB device is configured to load balance all TCP connections with a destination port number of 443 to a special set of servers. These new servers are called “SSL proxy servers” or “SSL offloaders”. The SLB selects an SSL proxy server, the SSL proxy server terminates the TCP connection, performs an SSL key exchange (or “handshake”) and decrypts the data sent by Bob’s PC (note: complete packet flow not shown).
3) The SSL proxy server now acts as a TCP client, initiates a new TCP connection, and sends the HTTP request in clear text back to the HTTP VIP on the SLB device.
4) The SLB device notes that the request contains a cookie, and directs the request to server A.
5) Server A completes the transaction, and returns “Transaction complete: Print this page for your records. Thank you for your purchase” to the SLB device.
6) The SLB device forwards the reply from server A to the SSL proxy server.
7) The SSL proxy server encrypts the forwarded reply and sends it back to the SLB device in the existing HTTPS connection.
8) The SLB device finally returns the HTTP reply back to Bob’s PC.
There is a side benefit of this approach. SSL is extremely processor intensive, and offloading this SSL processing to SSL proxy servers can speed overall site performance. SSL proxy servers that are sold as appliances[3] often have some form of hardware acceleration, but even without such hardware there is an offload advantage (however even better overall site performance can often be realized if the money that would be spent on the SSL proxy servers is instead spent on additional Web servers). On the downside, this method adds considerable complexity to the site topology and data flow. Furthermore, this approach adds a security concern because personal information such as credit card numbers is sent in clear text across a segment of the network. Despite the fact that this traffic should flow only on the internal network (not out to the Internet), this security issue is the most common objection for financial and other such sites. There are several variations of this topology that are intended to address these concerns.
To address the complexity issue, or at least provide the appearance thereof, most SLB vendors now offer an “integrated” SSL offload feature (with the SSL proxy server inside the SLB device). Unfortunately most of these are not very well integrated with the SLB device. The actual implementation is functionally no different than what is shown above. For switch-based SLB devices, a “PC on a stick” approach is most often used, such that a physical server (i.e. a Pentium PC with motherboard, NIC, etc.) is placed in the SLB device enclosure, sharing power and cooling, and communicating with the SLB device as if it were external (via TCP). The configuration and administration of these “PC on a stick” solutions is usually almost identical to that of the appliance based products, i.e. it is required that the user configure the stick (or “blade”) as if it were an external device. The most obvious advantage of this “PC on a stick” approach is reduced footprint. For SLB solutions that are themselves PC or “appliance” based, the SSL proxy server is run on the same motherboard and processor as the load-balancing software. In these cases, where the SSL proxy can be truly integrated such that it does not need to be configured and maintained independently, there is genuine reduced complexity over external SSL proxy servers. Truly integrated systems also enjoy much better overall efficiency, as the SLB and SSL modules can access the same memory space. In contrast, the independent SSL proxy server solutions (either “PC on a stick” inside the SLB enclosure, or an external appliance) introduce a significant amount of system overhead as traffic must be passed back and forth between the SLB and the SSL proxy server. The obvious disadvantage of an integrated SSL approach: the additional SSL module, be it hardware or software, adds to the cost of the SLB device. If for some reason you decide to change to a different model or different brand of SLB, you lose your investment in the integrated SSL proxy server.
To address the security issue, opening up opportunities for financial sector customers, most SLB vendors also support encryption of the connection between the SSL proxy server (internal or external) and the Web servers. While solving the security issue, this approach creates some new issues of its own:
a) It effectively doubles the load on the SSL proxy server itself, and negates any gains in SSL offload mentioned above. To get around this issue, most vendors have implemented something called “connection pooling”. Connection pooling is by no means new. Database and other application developers have been using it for at least a decade. The idea is this: some number of connections are pre-established between the SSL proxy servers and the Web servers. When requests come in to the SSL proxy servers they are sent across one of these existing connections. This approach has the additional advantage of offloading TCP handshakes (not nearly as processing intensive as SSL, but still meaningful savings). One major disadvantage of this approach is that it hides the original IP address of the client from the Web servers. Some Web server applications must see the original client IP address to record profiling data, calculate the location of the user and insert appropriate advertising, etc. Most of these SSL proxy servers have the capability of passing the original client IP address in a new HTTP header field, but if the application on the Web server is not programmed to look at this field, the functionality is of no use.
b) It again hides the cookie so that the SLB device cannot read it! For SSL proxy server solutions that are truly integrated (i.e. the SLB and SSL functions share the same processor and memory), this is not an issue, as the SLB device is the SSL proxy device. For the PC on a stick implementations, the only workaround is to not use the load-balancing capabilities of the original SLB device, but instead use the SSL proxy server to do the load-balancing. Indeed some so called “integrated” solutions have two totally independent load-balancers in one physically chassis, running different operating systems and code bases, unable to share state information such as connection tables and cookies, and requiring independent configuration as if they were two devices from two different vendors.
Despite the additional complexity and security issues, many customers solve the shopping cart persistence issue in exactly this way.
Alternative Solution
The alternative solution involves the use server-issued HTTP redirects, combined with a configuration on the SLB device to handle failure scenarios[4].
This solution leverages the fact that by and large all Web sites use relative (as opposed to absolute) links within HTML content. The reason that sites use relative links is that absolute links are too difficult to maintain, as the HTML/script content would need to be changed every time content was moved between virtual directories, and every time an additional host name was added. In the case of relative links, something called the “BaseURI” is prepended to the link that appears in the HTML. The BaseURI is specified either by an HTML “BASE” tag in the page, or by the RequestURI (which is simply the URI/URL used to originally access the page). Clear as mud? Let’s try an example. Bob’s PC makes a request to http://www.buysomebooks.com/. The site returns the first page (or “default page”) of HTML as follows:
<html>
<body>
<a
href="/listofbooks.html">Click Here for List of Books</a>
<br>
<a
href="http://www.amazon.com/">Click Here to Buy Books from Someone
Else</a>
</body>
</html>
Because there is no BASE tag in the HTML, the BaseURI is the same as the RequestURI, which in this case is http://www.buysomebooks.com/. The first line after the “body” tag is a relative link. If Bob clicks on this link the browser will make another HTTP GET request to the URL http://www.buysomebooks.com/listofbooks.html. The second link is an absolute link to the Amazon.com site. If Bob clicks on this second link, the BaseURI will not be used.
The diagram below shows an example of the flow:
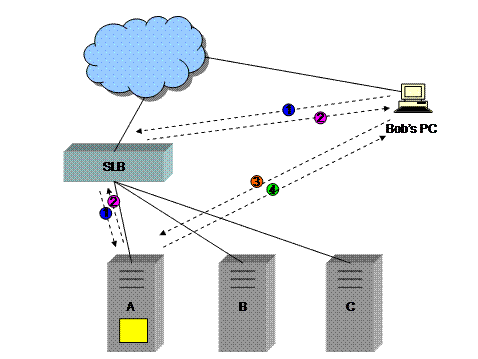
1) Bob’s PC makes a request to the VIP at http://www.buysomebooks.com/. The SLB load-balances the request to server A.
2) Rather than replying with the default home page of the site, server A replies with an HTTP redirect to a URL that is unique to that server. The response looks something like:
HTTP/1.1
302 Location Moved
Location:
http://wwwA.buysomebooks.com/
Configuring servers to behave this way is quite simple. It can be configured statically using the server administration interface (for example in the Properties dialogs in Microsoft IIS), or dynamically using server side script. A reference on how to this in Active Server Pages can be found on the Microsoft Support site at:
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dnasp/html/aspwsm.asp
in the section titled “ASP Session Aware Load-Balancing”.
3) Bob’s PC follows the HTTP redirect and connects directly to server A (this connection still may be through a physical interface on the SLB device, but the request is not load-balanced).
4) Server A replies with the default home page. Because the BaseURI is now that of server A, all subsequent requests that are the result of relative links will go to server A without being load balanced.
The example HTML above does not cover the case of an HTTPS link for the final order submission page. If the order submission page had an input or form action, resulting in an absolute link being used in the “Complete Transaction” button from the original example, this solution would not work. Again, in most all Web site implementations there is no use of absolute links within the link graph, even for HTTPS. HTTPS links are normally created dynamically, and the host name portion of the URL is obtained from the RequestURI. In Microsoft ASP the host name portion of the URI is obtained using the following object:
Request.ServerVariables(“SERVER_NAME”)
But this is no news to Web developers, as they will surely be familiar with this procedure.
Session Expiration
There are many ways to specify the duration of a user session, and many things users can and will do to foul things up. Here are some ways persistence can get fouled up even with HTTP cookies:
- If no specific expiry time is set on the cookies, the session duration is the period of time that the user continues to use that browser instance. If the user closes the browser, or simply opens another browser from the Start menu, the new instance will not send the cookie. Persistence is broken.
- If an expiry time is set to, say, to 20 minutes, if the user comes back after 21 minutes then persistence is broken.
- A cookie with a fixed expiry time (called a “permanent” cookie) is stored on disk and persists even if the browser is closed. It is shared between all browser instances, but only of the same kind of browser. That means if the user has, say, Internet Explorer open because they clicked a link in an Outlook e-mail message, but normally starts Netscape from a desktop icon, the session cookies will not be shared. Persistence is broken.
- Cookies are indexed by the FQDN when stored by the browser (either in RAM or on disk). That means if the user accesses the site by a different FQDN during a session, the cookie will not be sent, and persistence will be broken. An example of how this can happen: a user starts by accessing a bookmarked FQDN such as www.ciscosystems.com, then surfs off to another site, and later comes back to the Cisco site by typing www.cisco.com in the Location area of the browser. A similar way this can happen: the user starts with the bookmarked www.ciscosystems.com, surfs to another site, and later returns to the Cisco site via a cross-site link (which must be absolute) which uses the FQDN www.cisco.com.
As you can see, there are many ways that session persistence can be broken even with the use of cookies. There is no load balancer feature that can be or has been added to address these issues, and there is no workaround other than to simply live with some level of broken sessions.
Likewise there are plenty of ways to foul up the alternative solution described in this paper. Generally, as long as a user continues traversing the link graph within the site, they will be “stuck” to the same server. Otherwise persistence is broken. If the user surfs away to a different site and then returns by again typing in the original URL (in this example www.buysomebooks.com) then persistence will be broken. Also, if there are cross-site links and users hop back and forth between sites, persistence will be broken. In practice, most users do not re-type the URL or hop between sites, and many Web site customers seem to be happy with this type of solution, achieving a reliable level of persistence over an extended period of time, and millions of requests.
Configuring the SLB to handle Server Failure
The solution described properly handles the case where a server fails before a user makes their first request to the site. In the above example, if server A was failed, the SLB device would have detected this via appropriate health checking, and would not have load-balanced the initial connection to it. This does not cover the case where a server fails sometime in the middle of the session. Now, clearly all session state stored in server memory is lost if the server fails mid-session. There is nothing the SLB can do to help this. The solution described here introduces a new problem, however. Because the user is now “stuck” to server A (or the host name wwwA.buysomebooks.com), if server A fails it will appear to the user as if the entire site has failed. If the user knew enough to edit the URL in the Location area of the browser, changing it back to www.buysomebooks.com, the request would go to the VIP on the SLB, and the session would start over on server B or C. As mentioned above, users do not typically edit the URL (or even notice that it has changed).
The SLB can be configured to solve this issue, however. The exact configuration will vary depending on the brand of load-balancer used, but most can be made to work. To solve the failure issue it is required that the connection flow be changed as follows. Instead of returning a redirect that points directly to the server, a redirect that points to an additional VIP on the SLB should be returned to the client. In this example, additional VIPs and corresponding DNS A records should be added for the following fully qualified domain names (FQDNs):
- wwwA.buysomebooks.com
- wwwB.buysomebooks.com
- wwwC.buysomebooks.com
Each of these additional VIPs should have only one corresponding server, usually called a Real IP (RIP). Each RIP should then have a designated backup server. The backups could be configured in a circular fashion, i.e. A’s backup is B, B’s backup is C, and C’s backup is A, or better yet if the SLB supports it the VIP can be the designated backup for each RIP (so that after a failure the restarted session will be load-balanced).
What About the Changed URL?
This solution does produce a visible change in the URL (e.g. wwwA instead of www). It should be noted that users do not need to remember these different URLs. Nevertheless, if your marketing department digs in its heals and takes issue with the visible change, the above alternative may not be a viable choice. Also, if a user decides to bookmark the site mid-session, the bookmark will be to the server-specific URL. Given the SLB configuration above, this does not create a reliability problem, but if a large number of users tend to bookmark pages in the middle of sessions, over time load-balancing could be skewed.
Yet another approach
If after all this the HTTP redirect solution does not appeal to you, there is one other alternative to terminating SSL before (or inside) the SLB:
1) Use cookies and the features of the SLB to persist subsequent HTTP requests to the same server.
2) Upon the first request, return a cookie to the client. This cookie specifies the FQDN of the VIP that corresponds to that server. (If desired, the same cookie could be used for passive mode persistence and this second function).
3) When the “Check Out” page is presented to the user, construct the HTTPS link dynamically using a script that pulls the value out of the cookie.
This solution is not likely to cause the aforementioned issue with bookmarks, as “Check Out” pages are not likely candidates to be bookmarked.
Conclusion
SSL offload (or SSL termination) combined with HTTP cookies provides an effective solution for persistence across HTTP and HTTPS requests, however SSL offload also adds significant cost and complexity. The solution presented here is one alternative to SSL offload, and is quite suitable and reliable for many sites. As with any SLB solution, there are tradeoffs. The best one can hope to do is find a solution that requires the minimum time and financial investment, meets the performance and reliability needs of the application, and minimizes complexity.
Copyright Tenereillo, Inc. 2003