Why DNS Based Global Server Load
Balancing (GSLB) Doesn’t Work
Pete
Tenereillo
3/11/04
Copyright Tenereillo, Inc. 2004
Preface
Fred:
I’ve got a plane to catch. How long does it take to get from Hollywood to LAX?
Joe:
Well, it depends which way you go.
Fred:
Well, I guess I would take the freeway, right?
Joe:
OK, that’s a technical question. I can answer that. The freeway route takes
about 20 minutes assuming an average speed of 60MPH.
Fred:
OK, thanks.
(Fred
spends an hour window shopping on Rodeo Drive., then two hours driving in bumper
to bumper traffic to LAX, misses his plane).
Fred:
(on cell phone to Joe) The traffic was terrible, and I missed my plane! You
said it would only take 20 minutes!
Joe:
Oh, you didn’t ask how long it would take if there was traffic.
Fred:
Is the traffic particularly bad at this time of the day?
Joe:
Are you kidding? Traffic is always bad. This is LA!
A
solution can be technically correct given certain assumptions, but if it
ignores known details, it is not worthy of discussion. Maybe as technologists
we want so much to believe that every problem has a solution, that sometimes we
overlook the obvious. Maybe there are so many details to consider that we get
confused. Maybe after a while we just stop caring.
Abstract
DNS
based Global Server Load Balancing (GSLB) solutions exist to provide features
and functionality over and above what is available in standard DNS servers. This
paper explains the pitfalls in using such features for the most common Internet
services, including HTTP, HTTPS, FTP, streaming media, and any other
application or protocol that relies on browser based client access. At this
point I could add “if the solution is expected to also (simultaneously) enhance
(or at least not damage!) high availability of browser-based Internet
services”, but I won’t, because GSLB solutions are always expected to work well with high
availability deployments. That is the obvious.
The punch line
High-availability
GSLB of general Internet browser based services[1]
is best accomplished by including the use of multiple A records, but the use of
multiple A records debilitates DNS based global server “load balancing” (i.e.
traffic control or site selection algorithms). Therefore to use global server
load balancing (or multi-site traffic control) features, which are of
questionable value in the first place (see Why DNS based Global
Server Load Balancing (GSLB) Doesn't Work, Part II), one must accept the
compromise of reduced
high availability. Read on for a technical explanation about why.
The fundamental purpose of GSLB
The
overwhelmingly most compelling reason that Internet sites are hosted in
multiple locations is high availability. If a catastrophic event causes one of
the sites to become unavailable, one or more remaining sites must be able to
service requests from users, such that business can be continued. Given the
following example, with servers hosted in sites in Los Angeles and New York
City:
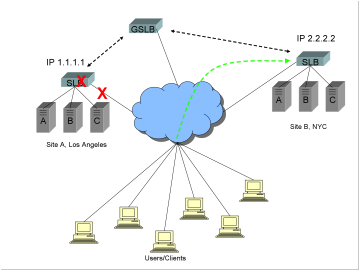
If the Internet
connection fails, or the power fails, or the switching or local server load
balancing (SLB) equipment fails, or a Denial of Service (DoS) attack occurs, or
if a catastrophic event causes the loss of the entire site, the GSLB device
should detect the failure and route requests to the remaining site, so that
clients can connect successfully and business can continue.
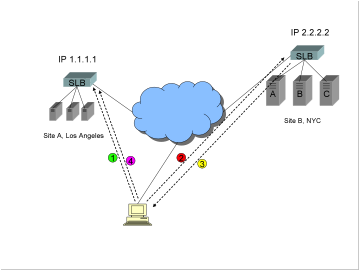
DNS resolution
At this
point a review of DNS resolution with GSLB is in order. Please feel free to
skip ahead if you are a DNS GSLB guru. The following diagram steps through a
client resolution of the Fully Qualified Domain Name (FQDN) www.trapster.net.
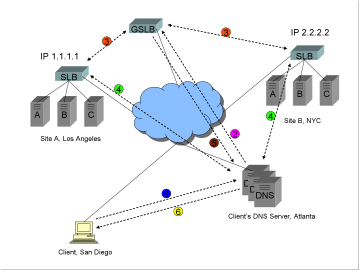
Site A
in Los Angeles has a virtual IP address (VIP) of 1.1.1.1, and Site B in NYC has
a VIP of 2.2.2.2. A GSLB device is acting as the authoritative name server for www.trapster.net. Upon a DNS query for www.trapster.net, the job of the GSLB is to
determine whether to return the IP address 1.1.1.1 or 2.2.2.2.
1)
The
stub resolver (a software program running on the client computer) makes a
request to the assigned local DNS server, which in this example is in the
client’s Internet Service Provider (ISP) DNS server farm in Atlanta, Georgia.
The client must receive either an answer, or an error. This is called a
“recursive” query. Note: the stub resolver program is not capable of “digging”
through the Internet to find the answer. That is the job of a DNS server.
2)
The
client’s DNS server performs an “iterative” resolution on behalf of the client,
querying the root name servers and eventually ending up at the authoritative
name server for www.trapster.net. In
this case the GSLB device is that authoritative name server.
3)
The
GSLB device performs some sort of communications with software or devices at
each site, gathering information such as site health, number of connections,
and response time.
4)
The
software or device at each site optionally performs some sort of dynamic
performance measurement, such as a round trip time (RTT), or topographical
footrace, or BGP hop count, back to the client’s DNS server.
5)
Using
the information gathered in steps 3 and 4, the GSLB device makes a
determination as to the preferred site, and returns the answer to the client’s
DNS server. The answer is either IP address 1.1.1.1 or IP address 2.2.2.2. If
the time to live (TTL) is not set to zero, the answer is cached at the client’s
DNS server, so that other clients that share the server will make use of the
previous calculation (and not repeat steps 2 through 4).
6)
The
DNS answer is returned to the client’s stub resolver.
After DNS resolution is complete, the client makes a TCP
connection to the preferred site.
Browser DNS caching
Microsoft
Internet Explorer (IE), Netscape Navigator/Communicator (Netscape), other
browser applications, and even some Web proxy cache applications and mail
servers, have built in “DNS caches”. This DNS cache is a sort of mini database
which stores a DNS answer for some period of time. DNS answers should, in
general, be stored for the amount of time that is specified by the DNS server
that gave the answer. This time is specified as a Time To Live (TTL).
Unfortunately, the DNS caches in browser applications cannot observe the TTL.
This is because a DNS query must be made via a standard available system call, gethostbyname() (or an equivalent derivative),
which returns one or more IP address associated with the queried name (that
system call does not allow the calling application to see the TTL). To get
around this issue, the browser application developers use a configurable TTL
value. In IE this value defaults to 30 minutes, and is configurable in the
Windows Registry on the client. In Netscape, the value defaults to 15 minutes,
and is configurable by the addition of a line of script to the prefs.js file.
The
frequency of the process of DNS resolution outlined above differs depending on
browser. Older browsers perform the process only one time every 30 minutes (IE)
or 15 minutes (Netscape), regardless of the number of times the user/client
connects to the site. Clicking on the Refresh/Reload button, even with control
or other key combinations, does not affect this behavior. The only way to clear
the DNS cache on these browsers is to exit and restart the browser (or reboot
the computer). In most cases “restarting the browser” entails closing all browser
windows, not just the windows that are open to the site in question - something
a user is unlikely to do in the event of a failed connection. Microsoft issued
a fix years ago, but at the time of this update (August 2007) a significant
portion of browsers still in use are impacted by this problem. More information
about DNS caching and browsers is available at http://www.tenereillo.com/BrowserDNSCache.htm
The browser DNS caching issue
Browser
caching has extremely significant implications for GSLB. If a given site
becomes unavailable because of a catastrophic failure, all clients that are currently using the
site will experience connection failures until the browser DNS cache expires or
they restart their browser or computer. Also, any clients that access DNS
servers that have cached the IP address of the failed site will also experience
connection failures. This is obviously unacceptable.
The
following diagrams will help demonstrate the magnitude of this issue. Take a
simple active/backup site scenario, the most simple and most popular of all
GLSB configurations, and financial industry site (stock/bond trading, on-line
banking, etc.):
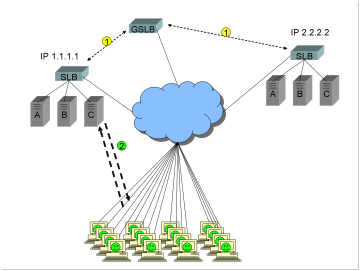
The fictitious
site www.ReallyBigWellTrustedFinancialSite.com
configures Site A in Los Angeles as the primary site, with Site B as the backup
site.
1)
To
accomplish this, a single DNS answer, or “A record”, with the IP address of
1.1.1.1, is returned in response to a query for the FQDN www.ReallyBigWellTrustedFinancialSite.com.
A GSLB device is deployed, using super dooper advanced health checking
technology.
2)
Thousands
of users are connected to Site A, happily conducting business. All have the IP
address 1.1.1.1 cached in their browsers.
Now
disaster strikes, as shown in the following diagram:
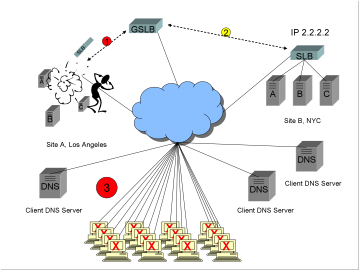
1)
The
super dooper advanced health checking on the GSLB instantly detects a failure.
2)
The
GSLB notes that Site B is still healthy, and begins returning the IP address
2.2.2.2, so as to route any new requests to site B.
3)
All
existing users already have Site A, IP address 1.1.1.1, cached in their
browsers. There is nothing
the GSLB device can do to help these users, because clients do not make new DNS
requests until the browser cache expires.
The
site is effectively down for up to ½ hour for all existing clients, completely
outside the control of the super dooper advanced health checking GSLB.
As if
that’s not bad enough, it gets worse, as shown in the following diagram:
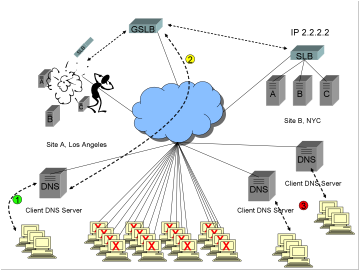
1)
Some
new clients share a DNS server which does not have the A record with answer
1.1.1.1 cached. These clients make requests for www.ReallyBigWellTrustedFinancialSite.com.
2)
The
client’s DNS server performs an iterative resolution on behalf of the client (at
least the first to request), ending up at the GSLB, and the GSLB returns the A
record for the healthy site, 2.2.2.2. All is happy.
3)
Some
other new clients share DNS servers that do have the A record with answer
1.1.1.1 cached. This is either because these new requests are within the TTL
window set by the GSLB, or because the DNS servers ignore low or zero TTLs
(which, in fact, some DNS servers do). Because the answers are cached, the DNS
servers do not query the GSLB, and do not know the site with IP address 1.1.1.1
is down. These other new clients also see the entire site down for up to ½
hour, completely outside the control of the GSLB.
The solution to the browser caching issue
The
long-standing solution to the browser DNS caching issue is for the authoritative
name server (or GSLB) to return multiple DNS answers (or “A records”).
The use of multiple A records is
not a trick of the trade, or a feature conceived by load balancing equipment
vendors. The DNS protocol was designed with support for multiple A records for
this very reason.
Applications such
as browsers and proxies and mail servers make use of that part of the DNS
protocol.
The
following diagrams show how this works:
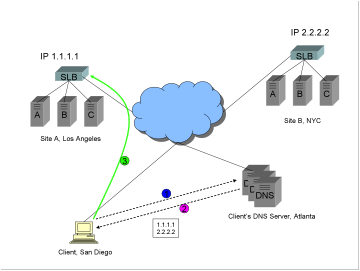
1)
The
client requests a DNS resolution for the FQDN www.trapster.net.
2)
After
iterative resolution (not shown), the client’s DNS server returns A records
with IP addresses 1.1.1.1 and then 2.2.2.2 (in that order).
3)
The
client makes a connection to Site A, IP 1.1.1.1.
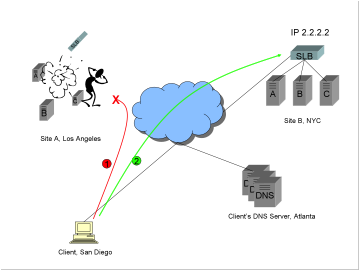
1)
While
the client is happily conducting business on Site A, a catastrophic event takes
the site out completely. The connection to the site is lost.
2)
Because
the second A record with address 2.2.2.2 was originally sent, the client
silently connects to Site B[2].
Note: Depending on the architecture of the business application, some state
such as sign-on information, a shopping cart, or a financial transaction, may
be lost because of the catastrophe, however the client can still connect to the
replicated site and begin conducting business again.
The
return of multiple A records does not require a GSLB device, but most GSLB
devices are capable of returning multiple A records. All major DNS servers
support the return of multiple A records, and essentially all commercial
Internet sites that support browser based clients return multiple A records for
this reason.
An Axiom
The only way to achieve
high-availability GSLB for browser based clients is to include the use of
multiple A records
There
are a plethora of alternative solutions available, but none of them solve the
issue effectively (see the section on “Alternative methods” below). Short of
modifying the Windows Registry on every PC on the Internet that might
potentially access the site, multiple A records is the only way.
Why the multiple A record solution doesn’t work with GSLB
As
mentioned, DNS servers are able to return multiple A records. GSLB devices are
also able to return multiple A records. Internet sites already have DNS
servers. Internet site owners purchase GSLB devices, often for as much as
$30,000 per unit, for the features these devices provide over and above the capabilities that
come for “free” with DNS servers.
The
problem:
None of these features work reliably
in conjunction with multiple A records.
Not
basic two site active standby, not static site preferences, not IANA table
based preferences, not DNS persistence, not RTT or footraces, not geotargeting
based redirection… none of them work! The following diagram will show why.
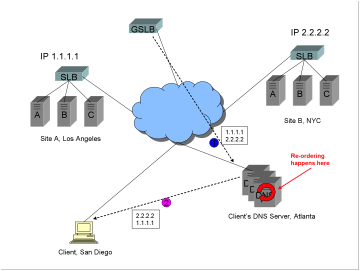
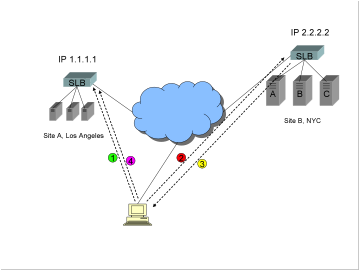
The
GSLB DNS resolution takes place as in the previous example (steps such as
health checking, RTT measurements, etc. removed for the sake of simplicity).
1)
Let’s
say the GSLB device prefers Site A, IP address 1.1.1.1. It returns the list of
DNS answers in the order:
·
1.1.1.1
·
2.2.2.2
2)
The
client’s DNS server receives that answer and places it into its cache. The
client’s DNS server now returns the list either in the order:
·
1.1.1.1
·
2.2.2.2
Or in the order
·
2.2.2.2
·
1.1.1.1
Most
all current commercial GSLB solutions return multiple A records in what is
sometimes called an “ordered list”, assuming that the order will be passed all
the way to the client stub resolver unchanged[3].
Unfortunately, that assumption is incorrect.
The order in which the addresses
are returned can and will be changed by the client’s DNS server!
DNS
servers do this to help with even distribution of traffic to multiple sites,
and this is default behavior on most DNS servers at most providers[4].
It was previously thought that setting a TTL value of zero in step 1 above
would prevent this re-ordering from happening, but unfortunately that is not
true. Because the order of the list of A records can and will be changed,
completely outside the control of a GSLB device or authoritative name server,
it is not possible to deterministically prefer one site over another.
Site cookies: Guess what? Those don’t work either!
Most
Web commercial sites that are hosted in multiple locations require session
persistence, i.e. if a client connects to Site A, they must continue to connect
to Site A for the duration of the session. Even sites that are totally
synchronized work better with some level of persistence, because it is
impossible to synchronize in real time.
There
is a silver lining with the browser DNS caching issue. After a client resolves www.trapster.net to, say, Site A, IP address
1.1.1.1, that client will continue to connect to Site A until the browser DNS
cache expires. As mentioned before, this time is 30 minutes on IE, and 15 on
Netscape. Clearly this method alone will not suffice for persistence if session
times are commonly greater than 30 (or 15) minutes, because the at that point
the browser DNS cache will re-resolve, and the client will likely end up on the
wrong site. Also, the 30 minutes and 15 minutes, respectively, are fixed
timers, not inactivity timers. For example, if a user visits www.trapster.net, and then answers a phone
call that takes 29 minutes, and then after the phone call returns to www.trapster.net to begin ordering some
merchandise, the browser will re-resolve after only one minute, now likely
directing the user to the wrong site.
This
DNS client cache expiration issue is so widely known, that essentially all SLB
vendors have implemented a fix for it. This method is usually called the “site
cookie” method, and it is usually implemented only for HTTP (though it could
work, and is implemented by at least one vendor, for some streaming media
protocols). Here’s how it works:
1)
The
client resolves www.trapster.net to Site
A, IP address 1.1.1.1. The client connects to Site A, and begins conducting
business. In the course of the connections to Site A, the SLB at Site A inserts
an HTTP cookie that indicates which site (and optionally which server) the
client should connect to.
2)
After
some period of time the client browser’s DNS cache expires, and the client
re-resolves, this time to Site B, IP address 2.2.2.2. The IP address 2.2.2.2
will now be cached in the client’s browser for the next 30 (or 15) minutes. The
client now makes a connection to Site B. When the client connects to Site B, it
sends the site cookie indicating that the session should be at Site A.
3)
The
SLB at Site B sees this cookie, and sends an HTTP redirect. The FQDN portion of
the URL in the HTTP redirect cannot be www.trapster.net,
because the IP address 2.2.2.2 is still cached in the client’s browser. Also,
the IP address 1.1.1.1 probably cannot be used, because server software and SSL
certificates will usually not work properly if requests do not use a DNS name.
For this reason, a site-unique FQDN is almost always set up. In this case the
HTTP redirect would be to, say, www-a.trapster.net (or maybe site-a.www.trapster.net).
4)
The
client now reconnects to the same site using www-a.trapster.net and continues
conducting business.
As
shown below:
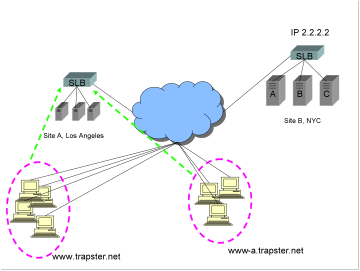
After
some period of time, and especially for sites that experience long session
times (such as stock trading or financial sites), a large percentage of users
will be connected via the site-unique FQDN. Also, even for short session times,
some users will bookmark the unique site FQDN www-a.trapster.net.
Because
there are users that will access the site using www-a.trapster.net, for
reliable high availability it is required that multiple A records are returned
not only for www.trapster.net, but also
for www-a.trapster.net. If both IP addresses 1.1.1.1 and 2.2.2.2 are returned
in response to the query for www-a.trapster.net, the client may connect to
either Site A or Site B!
Site cookies do not work
properly with multiple A records, for the same reason DNS based GSLB does not
work properly with multiple A records!
Is GSLB health checking beneficial?
We have
established that multiple A records are necessary, but the remaining question
is “are they sufficient for sites that support browser based clients?”. Browser
based clients do their own sort of “health checking” when multiple A records
are returned. Again, this is why multiple A records were designed into the DNS
protocol. There may be a case for not returning the A record for a site that is
known to be down, but there are also many cases where the A record for a dead
site should
be returned. This section presents such a case. Many types of failures are
transient, i.e. the same problem happens at many different sites sequentially
or simultaneously. Examples:
1)
A
power failure may affect data centers in a region, and as the power grid is
adjusted, may affect data centers in other regions.
2)
Denial
of Services (DoS) attacks are usually launched against IP addresses. A DoS
attack may first affect IP address 1.1.1.1, and then IP address 2.2.2.2.
3)
A
computer virus may first affect data center A. It may take ½ hour for site
personnel to remove the virus. During this time, the virus may also affect data
center B.
4)
An
ISP may have an issue with routers that sequentially affects different regions
of the country.
Given
the previous examples, with Site A, IP address 1.1.1.1, and Site B, IP address
2.2.2.2, if an SLB or GSLB device (or even BIND with a health checking script)
detects that, say, Site A is failed, should a single A record with IP address
2.2.2.2 be returned? If Site B, IP address 2.2.2.2, subsequently fails, but
Site A comes back up, within a ½ hour window, it would have been better to
return both A records, even if health checking detected a failure. Remember,
returning multiple A records is rarely a negative, as clients will silently
connect to the first healthy site in the list of A records.
Alternative methods
There
is a less severe sort of failure that can also occur. Servers at one of the
sites may fail, while the power, Internet connection, and switching and SLB
equipment remain operational. There are many commercially available solutions
to that problem. These include backup redirection, triangulation, proxying, or
NATing. Those are discussed here for the sake of completeness, but as this
section will show, those solutions to the lesser problem of server failure do
not in any way solve the more important issue of total site failure.
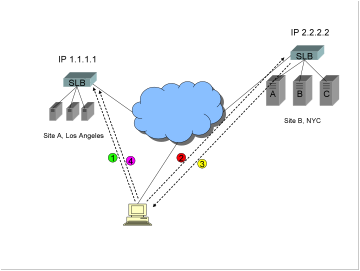
Triangulation
Triangulation
is a recovery method that works for all IP protocol types.
1)
Client
already connected to Site A, happily surfing away.
2)
The
servers at Site A now fail (but in this example the SLB, Internet connection,
switches, routers, power, etc. are all OK). Software running on the SLB at Site
A detects the server failure. Of course any existing TCP connections are lost,
but the client will attempt to reconnect. The SLB at Site A now forwards
packets that are part of a new connection request by the client to the SLB at
Site B over a pre-established TCP tunnel.
3)
The
SLB at Site B chooses a new server to service this client connection, and then
returns the packets directly to the client, using the spoofed IP address
1.1.1.1.
Backup redirection
Backup
redirection works only for protocols which have application layer redirection
capabilities (e.g. HTTP, HTTPS, some streaming media protocols).
1)
The
client makes a request to Site A. This request is to, say, the FQDN www.trapster.net, which was resolved to the
IP address 1.1.1.1.
2)
The
SLB at Site A, knowing that all servers at Site A have failed, issues an HTTP
redirect to send the user to Site B. A different FQDN, say www-b.trapster.net,
must be used. If the HTTP redirect was to www.trapster.net,
the client would just use the IP address that was currently cached (1.1.1.1)
and end up back at Site A. Also, the URL in the HTTP probably cannot reference
an IP address, as most servers, SSL certificates, etc. require that the site be
accessed via an FQDN, not an IP address.
3)
The
client now connects to Site B.
IP proxy and NAT
IP
proxy (and NAT) work for all IP protocol types. They are not described in
detail here. Each of these methods, upon failure of all servers at Site A,
would load-balance connections from the client to a VIP on the SLB at Site B,
much in the same way a local SLB would load-balance connections to local
servers.
The issue with triangulation, backup redirection, IP proxy, and NAT
These
methods will indeed help with disaster recovery if the Internet connection,
switching equipment, power, or local SLB equipment are all operational, i.e. it
is only the servers that have failed. If these methods are, however, used in
conjunction with multiple A records, the value these methods add is
questionable. To use these methods alone, without multiple A records, is to
miss the forest for the trees. If total site loss is not a concern, there is
not a strong argument for GSLB at all. It would probably be better to forget
GSLB altogether, leaving behind all of its costs and complexities, and locate
the sum total of all servers that would have been at two sites instead at one
site, with redundant power, Internet, switching, and SLB equipment.
That
said, high availability even in the case of catastrophe is the most fundamental
requirement of GSLB implementations, and is almost always a specified
requirement, therefore:
Triangulation, backup
redirection, IP proxy, or NAT, are neither necessary or sufficient for purposes
of high availability. Multiple A records are still needed for sites that
support browser based clients[5].
BGP Host Route Injection
There
is one more method, usually called BGP Host Route Injection (HRI), but also
called “Global IP” by at least two vendors. It is not simply a backup method
sometimes used in conjunction with DNS based GSLB, but rather a method used in
place of DNS based GSLB. Here’s a high level overview of how it works:
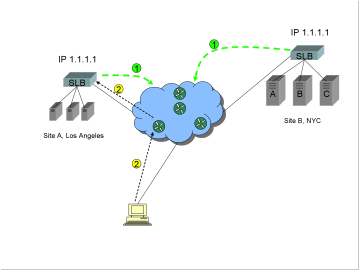
0)
(DNS
resolution takes place, only one IP address, 1.1.1.1, is returned in response
to a query for the FQDN www.trapster.net).
1)
Server
load balancers (or routers) at Sites A and B each advertise to the Internet
“I’m IP address 1.1.1.1”. Internet routers exchange metrics via BGP, and
propagate this information to the router closest to the client.
2)
The
client now connects to the topographically closest site.
Now all
servers, or even the Internet connection, power, SLB, or switching equipment
fail, or there is a catastrophic site loss.
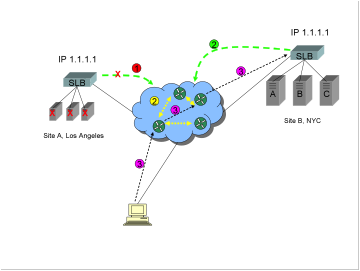
1)
The
SLB at Site A detects the server failure, and stops advertising via BGP that it
is IP address 1.1.1.1 (or the SLB or connection are destroyed, in which case
advertising also obviously stops).
2)
Route
convergence between Internet routers occurs, so that the path to Site A is
eventually removed.
3)
The
client now connects to IP address 1.1.1.1, but at Site B.
Though
in theory this method may look like the Holy Grail of GSLB, it is seldom
implemented. Here’s why:
·
Internet
routing is quite complex, and the practice of advertising the same IP address
for disparate locations does not work reliably. If route maps change during a
client session, packets may flow to Site A and Site B intermittently, so that
the client cannot successfully connect even if both sites are functioning
properly.
·
Route
convergence can take considerable time. In the case of a failure, the client
browser will time out, presenting a failure dialog. If the user persists in
manual reattempts, eventually a connection will succeed, but it is not uncommon
for this to take more than five minutes. Such down time is usually deemed
unacceptable for commercial Web applications.
·
BGP
route advertisements that are single IP addresses (hosts) are usually ignored
by Internet routers. A possible solution is to instead advertise an entire
network address, however doing so simply for the purpose of GSLB constitutes a
waste of expensive IP addresses (since only one, or maybe a handful, are
actually used).
·
Source
IP address filters (sometimes called “bogon” filters), configured on routers
for security purposes, often prevent devices from advertising IP addresses from
multiple locations. This problem is often solvable by negotiations with ISPs,
but is nevertheless another complication, as in practice “bogon” filters that
are removed by such negotiations are often inadvertently added back by ISP
personnel, causing downed sites, requiring trouble ticket calls, etc.
BGP HRI
is a sound approach for closed networks, and may be made to work for some
Internet applications, but is quite rare because it does not work in practice
nearly as well as it does in theory.
Conclusion
The
only way to achieve high availability GSLB for browser based clients is to
return multiple A records, but returning multiple A records diminishes any
possibility of deterministic site selection. Because of this features such as
basic two site active-standby, DNS persistence, RTT or footrace or BGP hop
count based site selection, IP address based geotargeting or IANA table based
selection are all effectively useless.
The
good news – now customers can use the $30,000/unit they would have spent on
GSLB devices to add more servers and inter-site synchronization capabilities!
Watering it down
At the
risk of helping the technically correct to obfuscate the obvious[6],
the following:
At
least in theory, a GSLB device could operate in a “best choices, round robin”
type fashion. For example, if a FQDN is hosted in two sites in Europe and two
sites in the US, the GSLB could determine that a given client is best served by
the Europe sites and return only the Europe A records to that client’s DNS
server. The client’s DNS server would then round robin between those. From the
following diagram:
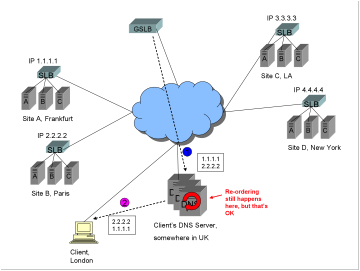
0)
As
before (not shown in diagram) the client makes a request for the FQDN www.trapster.net, the request ends up at
the authoritative DNS server for www.trapster.net
which is the GSLB device, the GSLB performs the selected algorithm and
determines that Frankfurt and Paris are better choices than either LA or New
York for that client.
1)
The
GSLB returns both A records 1.1.1.1 and 2.2.2.2.
2)
The
list of A records is re-ordered at the client’s DNS server, but in this case
that’s OK and expected. The client connects to either Frankfurt or Paris.
For the
purpose of this example, let’s arbitrarily choose the term “zone” to denote a
GSLB topography. Say sites A and B above are in the Europe GSLB “zone”, and
sites C and D are in the US zone. Such functionality would only work for global
sites that have content replicated in at least two datacenters in every given
zone that is to be GSLBed. If www.trapster.net
was instead hosted in datacenters in London, New York, and Tokyo, the “best
choices, round robin” solution would not be very useful. For a client in
London, the GSLB would need to return A records for London (which is
topographically close to the client), and also at least one of the others (New York or
Tokyo, neither of which are topographically close to the client). The client
would be equally likely to connect to London or one of the other sites. Clearly
such complications far diminish the intended purpose of GSLB site selection
algorithms. Furthermore, some site selection methods (such as footrace
variants) cannot work in a “best choices, round robin” fashion (exercise left
to the reader), and DNS persistence by definition does not work with “best choices,
round robin”. Though such a complex implementation could be made to work for a
handful of very large global sites, it is not a generally useful solution to
the problem presented in this paper.
Copyright Tenereillo, Inc. 2004